
Coreferensmodeller — nu også på dansk!
26.4.2021 10:58:06 CEST | Alexandra Instituttet | Pressemeddelelse
Blogindlægget er skrevet af Maria Barrett, Postdoc ved Institut for Datalogi på IT-Universitetet, og er udgivet på Alexandra Instituttets blog for NLP og dansk sprogteknologi på Medium: DaNLP
Coreferens er i Natural Language Processing (NLP) en opgave, hvor man skal finde alle tekstbidder (spans) i en tekst, der henviser til den samme entitet. En entitet kan være en person, et sted, en event eller en organisation, men det kan også være en ikke-navngiven hændelse/handling.
Som andre opgaver inden for NLP bliver coreferens løst med kunstig intelligens. I dette blogindlæg tager vi en teknisk tur ind i maskinrummet bag coreferens og præsenterer de første offenligt tilgængelige, danske coreferensmodeller, der bygger på kunstig intelligens.
Løsning af coreferens er en central underopgave for en række sproglige opgaver som fx automatisk at svare på spørgsmål ud fra en tekst eller lave et resumé. Disse er afhængige af, at modellen kan identificere alle benævnelser for fx en person i et dokument, uanset om denne er nævnt ved sit navn, et personligt stedord eller en anden nominalfrase.
Som med mange andre NLP-opgaver er det noget, som mennesker helt automatisk gør, når vi læser. Coreferens er et svært problem for et computerprogram at løse automatisk, fordi benævnelser kan være meget lange og også meget langt væk fra hinanden i et dokument.
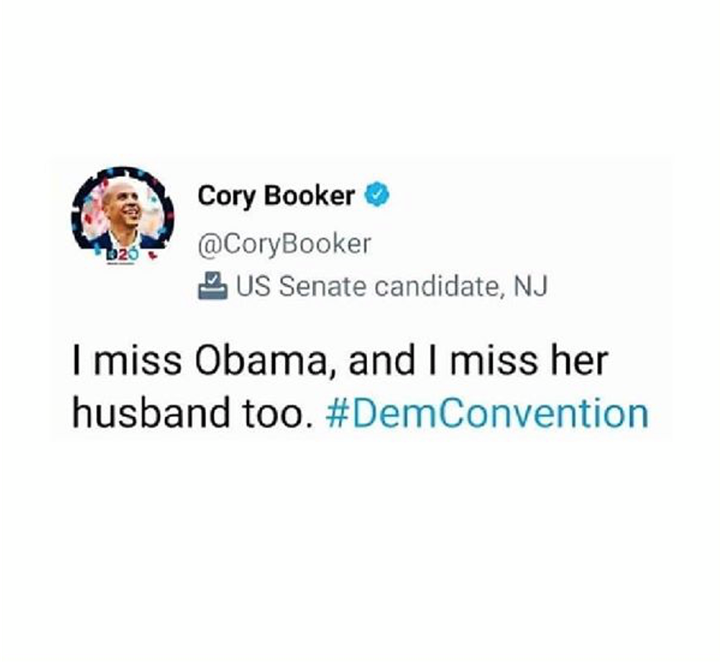
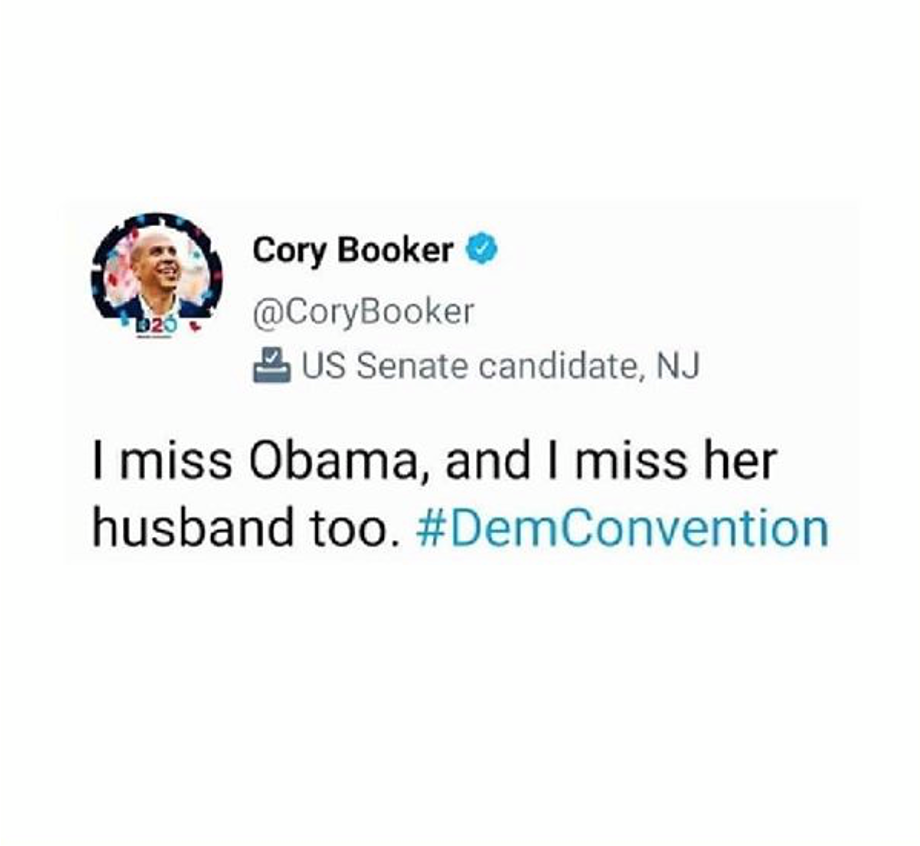
Som eksempel på et meget kort dokument, kan vi tage følgende tweet:
For at se dette indhold fra miro.medium.com, så skal du give din accept på toppen af denne side.
Input til en coreferens-model er et helt dokument, i dette tilfælde et enkelt tweet. Modellen identificerer og grupperer herefter de tekstbidder, der henviser til samme entitet. I tweetet vil en god coreferensmodel identificere følgende tre klynger:
( I, I)
(Obama, her)
(her husband)
Det vil sige, at en coreferensmodel som input tager et dokument og som output leverer klynger af tekstbidder, der henviser til samme entitet.
Dansk coreferens-data
For at træne en coreferensmodel ved hjælp af kunstig intelligens og for at evaluere hvor god den trænede model er, skal man bruge data, der er korrekt annoteret af et menneske, en såkaldt guldannotering. I dette afsnit fortæller jeg om den danske coreferensannotering vi har brugt til at træne og evaluere de danske coreferensmodeller med.
Vi har brugt en annotering fra the Copenhagen Dependency Treebank project (Kromann & Lynge, 2004). Annoteringen er ikke færdiggjort for hele træbanken, men dækker ca 2/3 , men er fint dokumenteret. Det annoterede sæt består af 64.076 tokens fordelt på over 341 dokumenter. Det er primært nyhedstekst, men også noget fra forskellige tidsskrifter.
Datasættet er tilgængeligt gennem DaNLP sammen med dokument-id’er for vores trænings- udviklings- og evaluerings-split så alle kan træne og evaluere deres egne coreferensmodeller.
Neurale coreferens-modeller
I dette afsnit vil vi beskrive de tekniske detaljer for de to danske coreferensmodeller, der begge bygger på kunstig intelligens. Vil du hellere gå direkte til evalueringsresultatet for modellerne, så kan du læse mere under ‘Resultater’ nederst i artiklen.
Løsning af coreferens er typisk blevet behandlet i flere stadier. Først har modellen detekteret mulige benævnelser, og derefter lært om de parvis er coreferente. Det er regnemæssigt effektivt og skalerer godt til lange dokumenter. Man har typisk haft flere modeller med i træningsloopet, fx en syntaksparser til at opmærke grammatiske strukturer og eventuelt også regelbaserede elementer (altså elementer i modellen der ikke bygger på kunstig intelligens). Det vil sige, at en coreferensmodel tidligere bestod af flere forskellige modeller, der blev trænet separat. Det kan man læse mere om i Ng (2010).
Men i 2017 præsenterede Lee et al. den første end-to-end coreferens-model, der er en ren neural model uden behov for andre modeller. “End-to-end” betyder, at modellen både finder benævnelser og grupperer dem i samme træningspas. Der er heller ikke brug for en separat syntaksparser. Uden benævnelsesdetektion som et separat trin, kan alle tekstbidder i princippet være en benævnelse, men for at reducere regneaktiviteten udregnes modellen en score per par af benævnelser (fundet i tidligere iterationer) og mulige tekstbidder. Listen af disse bliver iterativt og aggressivt beskåret for at reducere antallet af beregninger. Benævnelses-tekstbid-repræsentationerne bruger både teksbidden selv og konteksten omkring den i repræsentationen. Modellen bruger en bidirectional LSTM for at encode teksten og konteksten. Denne model viste i 2017, at den var bedre end tidligere metoder på det engelske data fra CoNLL-2012 shared task, som kommer fra Ontonotes (Pradhan et al., 2012), som er det engelske benchmark-datasæt.
I 2018 lavede Lee et al. en opdatering af ovennævnte model i artiklen Higher-order Coreference Resolution with Coarse-to-fine inference . Den tidligere model fra 2017 er en førsteordensmodel, fordi den kun forholder sig til par af tekstbidder. Lee et al. (2018) påpeger, at førsteordensmodeller kan rumme globale inkonsistenser. Higher-order-modellen i Lee et al. 2018 forholder sig til flere mulige kandidatspans per (mulige) span i en matrice (og ikke udregnet som en parvis score).
Oprindeligt blev begge modeller brugt med word-embeddings som vektorrepræsentationer for ordene, men Joshi et al. (2019) viste, at man kunne få endnu bedre resultater på engelsk, hvis man i stedet brugte SpanBERT (Joshi et al., 2020) og BERT (Devlin et al., 2019). Da der ikke er en dansk SpanBERT, er de danske modeller trænet på andre præ-trænede repræsentationer fra transformere. Vi har brugt dansk BERT , som er en uncased model og to flersprogede, cased modeller: Multilingual BERT citat og XLM-Roberta (Conneau et al., 2020). I stedet for den originale tensorflowimplementering har vi brugt pytorchimplementeringerne fra AllenNLP.
Resultaterne for den danske coreferens-model på det danske testssplit, der indeholder 28 dokumenter, kan ses i tabellen nedenfor. Modellen er trænet med early stopping over 12000 epochs, og vi har tunet modellernes læringsrate, og læringsraten for transformermodellerne over 50 epochs.
Resultater
Den bedste model er Lee et al. 2018 med udgangspunkt i XLM-Roberta. Alle modellerne kan findes som del af DaNLP toolkittet.
For at se dette indhold fra miro.medium.com, så skal du give din accept på toppen af denne side.
Gennemsnit af F1, precison og recall fra MUC, CEAF og B3 samt mention recall for hver af de seks danske coreferens-modeller.
Hvordan skal resultaterne forstås?
Mention recall er en procentsats for, hvor mange af de korrekte tekstbidder, der er fundet. Men derefter skal man finde en god måde at kvantificere, hvor korrekt de er clustret.
Coreferens har (mindst) et problem: Det er svært at evaluere. Overvej fx hvilken af følgende modeller der er bedst (eller mindst dårlig) for tweetet ovenfor. Den korrekte annotering er — som tidligere nævnt:
(I, I) (Obama, her) (her husband)
Model 1: (I, I)
Model 2: (I) (I) (Obama) (her) (her husband)
Model 3: (I, I, her husband, Obama) (her)
De har hver især deres kvaliteter. Hvor model 1 kun har fundet 40% af de oprindelige tekstbidder, har den trods alt formået at gruppere disse korrekt. Model 2 og 3 har fundet alle de korrekte tekstbidder, men har grupperet dem forkert på hver deres måde.
Der er flere forskellige metrikker til at forsøge at måle overensstemmelsen mellem to forskellige annoteringer, men de fleste er enige om, at ingen af dem er gode nok til at stå alene. Selvom et gennemsnit af flere halvdårlige mål ikke giver et perfekt resultat, er der mange, der bruger et gennemsnit af følgende tre metrikker: MUC, B3 og CEAF. De har hver en precision, recall og F1. Det er også disse gennemsnit, der kan ses i tabellen.
Referencer
Jeffrey Pennington, Richard Socher, and Christopher D Manning. 2014. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on Empirical Methods in Natural Language Processing (EMNLP).
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., Grave, E., Ott, M., Zettlemoyer, L. & Stoyanov, V. (2020). Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (pp. 8440–8451).
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019, June). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (pp. 4171–4186).
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019, June). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (pp. 4171–4186).
Joshi, M., Chen, D., Liu, Y., Weld, D. S., Zettlemoyer, L., & Levy, O. (2020). Spanbert: Improving pre-training by representing and predicting spans. In Transactions of the Association for Computational Linguistics, 8, 64–77.
Joshi, M., Levy, O., Zettlemoyer, L., & Weld, D. S. (2019). BERT for Coreference Resolution: Baselines and Analysis. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (pp. 5807–5812).
M.T. Kromann and S.K. Lynge. Danish Dependency Treebank v. 1.0. Department of Computational Linguistics, Copenhagen Business School., 2004. https://github.com/mbkromann/copenhagen-dependency-treebank
Lee, K., He, L., Lewis, M., & Zettlemoyer, L. (2017, September). End-to-end Neural Coreference Resolution. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (pp. 188–197).
Lee, K., He, L., & Zettlemoyer, L. (2018, June). Higher-Order Coreference Resolution with Coarse-to-Fine Inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) (pp. 687–692).
Vincent Ng. 2010. Supervised noun phrase coreference research: The first fifteen years. In Proceedings of the 48th annual meeting of the association for computational linguistics, pages 1396–1411. Association for Computational Linguistics.
Sameer Pradhan, Alessandro Moschitti, Nianwen Xue, Olga Uryupina, and Yuchen Zhang. 2012. Conll2012 shared task: Modeling multilingual unrestricted coreference in ontonotes. In Joint Conference on EMNLP and CoNLL — Shared Task, pages 1–40. Association for Computational Linguistics.
Joseph Turian, Lev Ratinov, and Yoshua Bengio. 2010. Word representations: A Simple and General Method for Semi-supervised Learning. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics.
Xu, L., & Choi, J. D. (2020, November). Revealing the Myth of Higher-Order Inference in Coreference Resolution. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 8527–8533).
Nøgleord
Kontakter
Lisa LorentzenCommunications Specialist
Kommunikation og Markedsføring
Billeder
{kind=link}
Links
Information om Alexandra Instituttet
 Alexandra Instituttet
Alexandra InstituttetÅbogade 34 · Rued Langgaards Vej 7
8200 Aarhus N · 2300 København S
+45 70 27 70 12https://alexandra.dk
DaNLP er et open-source repository, der kan bruges til at foretage automatiserede analyser af tekster på dansk. Målet med DaNLP er at lave en samlet oversigt over alle de danske ressourcer der allerede er til rådighed, samt at udvikle de værktøjer der mangler for at NLP på dansk bliver mere anvendeligt for alle og særligt for danske virksomheder. I DaNLP finder du derfor en oversigt over alle de tilgængelige datasæt og modeller, som allerede findes på dansk. Derudover finder du eksempler på kode, samt beskrivelser af hvordan du kommer igang med at bruge både datasæt og modeller.
Følg pressemeddelelser fra Alexandra Instituttet
Skriv dig op her, og modtag pressemeddelelser på e-mail. Indtast din e-mail, klik på abonner, og følg instruktionerne i den udsendte e-mail.
Flere pressemeddelelser fra Alexandra Instituttet
Alexandra Instituttet bringer glemt erhvervskvinde tilbage til Holstebros byrum med 3D-teknologi8.3.2026 06:15:00 CET | Pressemeddelelse
Ved hjælp af avanceret 3D-print har Alexandra Instituttet skabt en buste af erhvervskvinden Karoline Poulsen fra Holstebro – 60 år efter hendes død. Busten viser, hvor langt teknologien er kommet, og lægger kimen til bedre repræsentation af kvinder i det offentlige rum.
Gratis videreuddannelse til rådgivere skal gøre industrien cyber-robust19.2.2026 13:25:07 CET | Pressemeddelelse
Efter fire års intenst arbejde med at øge danske virksomheders cybersikkerhed er CyPro-samarbejdet nu nået til en vigtig milepæl. Det betyder, at værktøjerne kan tages i brug af rådgivere helt gratis.
Cybersikkerhedsbranchen går sammen om at løfte små- og mellemstore virksomheder i ny millionsatsning fra Industriens Fond30.1.2026 09:11:29 CET | Pressemeddelelse
23 virksomheder i den danske cybersikkerhedsbranche har valgt at donere ydelser svarende til 33,5 millioner kroner til en ny national satsning, der skal øge sikkerheden i små og mellemstore virksomheder.
Alexandra Instituttet får ny frontfigur for kunstig intelligens12.1.2026 09:30:00 CET | Pressemeddelelse
Mie Hvas er tiltrådt som Head of AI Lab hos Alexandra Instituttet. Her skal hun omsætte forskning til løsninger, der optimerer processer, analyserer data og giver danske virksomheder et teknologisk forspring.
Danmarks første til at udføre prøvning af cybersikre IoT-produkter og radioudstyr17.12.2025 08:30:00 CET | Pressemeddelelse
Som de første i Danmark er Alexandra Instituttet blevet akkrediteret, så de kan udføre prøvning af udstyr efter kravene i EN 18031. Dermed kan instituttet, der er specialiseret i IT og digitalisering, hjælpe virksomheder med at overholde Radioudstyrsdirektivet.
I vores nyhedsrum kan du læse alle vores pressemeddelelser, tilgå materiale i form af billeder og dokumenter samt finde vores kontaktoplysninger.
Besøg vores nyhedsrum